Zilnic oferim programe licențiate GRATUITE pe care altfel ar trebui să le cumpărați!

Giveaway of the day — PDF Text OCR Xtractor 3.2.2.20
PDF Text OCR Xtractor 3.2.2.20 a fost chilipirul zilei în 17 aprilie 2023

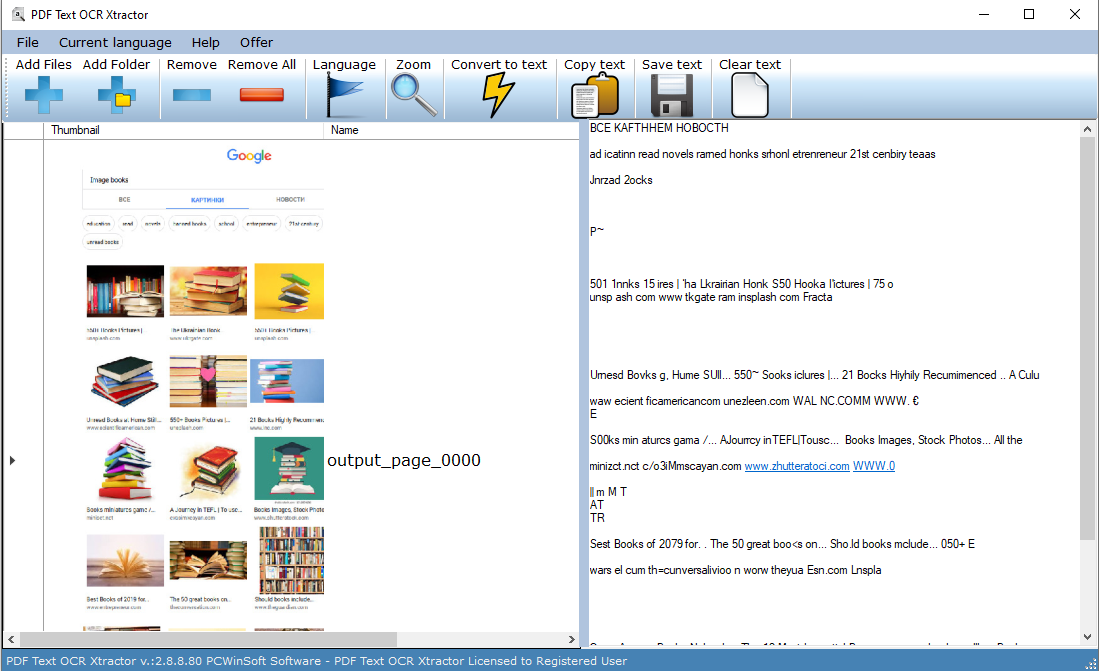
PDF Text OCR Xtractor este perfect pentru a extrage text din PDF-uri și din toate tipurile de formate de imagine populare, cum ar fi PNG, JPG, BMP și TIFF. PDF Text OCR Xtractor utilizează tehnologia Tesseract OCR. Tesseract este poate cel mai puternic și mai avansat software OCR de acolo și iată de ce: În primul rând, un pic de istorie. A fost dezvoltat de HP în 1994, dar în curând compania l-a lansat sub licență Apache pentru dezvoltare open-source. În 2006, Google a preluat proiectul și a sponsorizat dezvoltatorii să lucreze la Tesseract. Acum, înainte rapid și Tesseract a devenit cel mai puternic motor OCR care utilizează Deep Learning pentru a extrage texte din imagini (BMP, PNG, JPEG, TIFF etc.) și fișiere PDF. PDF Text OCR Xtractor acceptă peste 20 de limbi diferite și vă permite să setați parametrii de procesare personalizați pentru fișierele/imaginile sursă, cum ar fi netezirea și ajustarea DPI, creșterea contrastului și alte trucuri utile, înainte de a le analiza. PDF Text OCR Xtractor are o precizie ridicată și va primi orice imagine sau PDF pe care îl aveți în text editabil, care poate fi căutat. Conversia din imagine în text este rapidă. Caracteristici principale: 1. Utilizarea celei mai bune tehnologii OCR disponibile. 2. Suport pentru peste 20 de limbi diferite. 3. Transformări utile ale imaginii pentru a spori acuratețea documentelor dificile. Caracteristici suplimentare: 1. Cel mai ieftin motor Tesseract interfață grafică cu utilizatorul pe care o puteți găsi! 2. Suport pentru PDF și toate formatele de imagine comune, cum ar fi PNG, JPG, BMP.
The current text is the result of machine translation. You can help us improve it.
Cerinţe minime de sistem:
Windows 7/ 8.1/ 10/ 11 (x32/x64)
Publicist:
PCWinSoftPagina de pornire:
https://www.pcwinsoft.com/pdf-to-text.aspDimensiunile fişierului:
103 MB
Licence details:
lifetime
Preţ:
$29.90
Comentarii la PDF Text OCR Xtractor 3.2.2.20
Please add a comment explaining the reason behind your vote.